


Introduction
In the expansive realm of machine learning, supervised learning serves as a cornerstone, offering powerful predictive modeling tools. Supervised learning is a type of machine learning where the model is trained on a labeled dataset, meaning that each input data point (Input feature) is associated with a corresponding target value (response variable). This allows the model to learn the relationship between the input data and the target variable, enabling it to make predictions on new, unseen data.
Two fundamental branches of supervised learning are regression and classification.
Regression techniques enable us to understand and analyze the relationship between variables. In this article, we explore three key regression techniques:
Simple Linear Regression: Models the relationship between a single independent variable(input feature) and a dependent variable (output or response variable) using a straight line.
Multiple Linear Regression: Extends simple linear regression to model the relationship between multiple independent variables and a dependent variable. It allows for more complex relationships between the independent and dependent variables.
Polynomial Regression: Models the relationship between the independent variable x and the dependent variable y as an nth degree polynomial curve. Unlike simple and multiple linear regression, polynomial regression can capture non-linear relationships between the variables, offering more flexibility in modeling.
Classification techniques help us categorize data into predefined classes. Here, we'll delve into two significant classification techniques:
Binary Classification: Classifies data into two distinct categories.
Multi-class Classification: Categorizes data into more than two classes or categories.
Understanding these techniques is crucial for any aspiring data scientist or machine learning enthusiast. Let's dive into the intricacies of regression and classification in machine learning.
Regression
Regression, as mentioned earlier, is a supervised learning technique used to understand the relationship between independent and dependent variables. Once the model is trained to identify these relationships, it can predict a continuous numerical value from an infinite range of possible outcomes.
Simple Linear Regression
Simple linear regression is a basic regression technique that models the relationship between a single independent variable \(X\) and a dependent variable \(Y\) by fitting a straight line to the observed data points.

Equation:
The equation of a simple linear regression model is represented as:
\(Y = \beta_0 + \beta_1X + \epsilon \)
\(Y : \text{is the dependent variable}\)
\(X : \text{is the independent variable}\)
\(\beta_0 : \text{is the y-intercept (the value of ( Y ) when ( X = 0 ))}\)
\(\beta_1 : \text{ is the slope of the line (the change in ( Y ) for a unit change in ( X ))}\)
\(\epsilon : \text{represents the error term}\)
Example:
Let's say we have a dataset that represents the relationship between the number of hours studied \(X\) and the score obtained \(Y\) in an exam. We can use simple linear regression to model this relationship.
For example, if the simple linear regression equation for this dataset is:
$$\text{Score} = 50 + 5(\text{Hours Studied})$$
This equation implies that for every additional hour studied, the expected increase in score is 5 points. The y-intercept of 50 suggests that if a student studied for 0 hours, the expected score would still be 50.
This is a simple linear regression model where the relationship between the number of hours studied and the score obtained is represented by a straight line.
Multiple Linear Regression
Multiple linear regression extends simple linear regression to model the relationship between multiple independent variables \(X_1, X_2, ..., X_n\) and a single dependent variable \(Y\). Instead of fitting a straight line, multiple linear regression fits a hyperplane to the observed data points.

Equation:
The equation of a multiple linear regression model is represented as:
\(Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + ... + \beta_nX_n + \epsilon\)
\(Y: \text{is the dependent variable}\)
\(X_1, X_2, ..., X_n : \text {is the independent variable}\)
\( \beta_0 : \text {is the y-intercept}\)
\(\beta_1, \beta_2, ..., \beta_n: \text{ are the coefficients of the independent variables}\)
\(\epsilon: \text{represents the error term}\)
Example:
Let's say we have a dataset that represents the relationship between the number of hours studied \(X_1\) , the number of prep exams taken \(X_2\), and the score obtained \(Y\) in an exam. We can use multiple linear regression to model this relationship.
For example, if the multiple linear regression equation for this dataset is:
$$\text{Score} = 30 + 5(\text{Hours Studied}) + 10(\text{Prep Exams})$$
This equation implies that the expected score is equal to 30 plus 5 times the number of hours studied plus 10 times the number of prep exams taken.
In this case, the coefficients tell us how the score changes with each unit increase in the hours studied and the number of prep exams taken, while holding all other variables constant.
Polynomial Regression
Polynomial regression is a form of regression analysis where the relationship between the independent variable \(X\) and the dependent variable \(Y\) is modeled as an \((n)th\) degree polynomial. This allows us to capture non-linear relationships between the variables, offering more flexibility in modeling than simple and multiple linear regression.
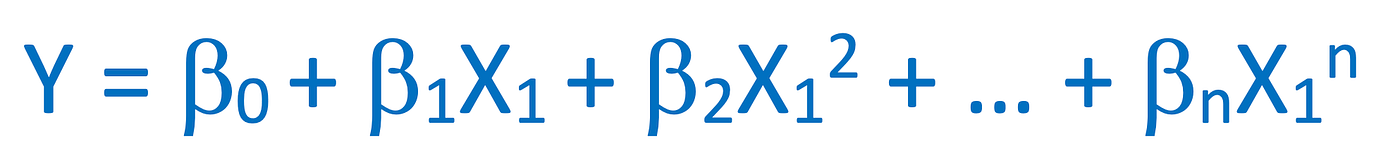
Equation:
The equation of a polynomial regression model is represented as:
\(Y = \beta_0 + \beta_1X + \beta_2X^2 + ... + \beta_nX^n + \epsilon\)
\(Y : \text {is the dependent variable}\)
\(X : \text {is the independent variable}\)
\(\beta_0 : \text{is the y-intercept}\)
\(\beta_1, \beta_2, ..., \beta_n: \text{ are the coefficients of the independent variables}\)
\(\epsilon: \text{represents the error term}\)
Example:
Let's say we have a dataset that represents the relationship between the temperature \(X\) and the number of ice creams sold \( Y\). We suspect that the relationship between temperature and ice cream sales may not be linear, so we decide to use polynomial regression to model this relationship.
For example, if the polynomial regression equation for this dataset is:
$$\text{Ice Cream Sales} = 10 - 2(\text{Temperature}) + 0.5(\text{Temperature})^2$$
This equation implies that the expected ice cream sales y depend on the temperature according to a quadratic relationship.
In this case, the coefficients tell us how the ice cream sales change with the temperature, taking into account both linear and quadratic effects.
Classification
Classification is a supervised learning technique used to categorize data into predefined classes or categories based on the input features (independent variables). The model is trained on a labeled dataset, where each input data point is associated with a corresponding target class (response or output variable). Once the model is trained, it can predict the class or category of new, unseen data points based on their features.
Binary Classification
Binary classification is a supervised learning technique used to classify data into two distinct categories or classes. The model is trained on a labeled dataset, where each input data point is associated with one of the two classes. The goal of binary classification is to predict the correct class label for new, unseen data points based on their features.
Equation:
Binary classification models don't have a specific equation like regression models. Instead, they use algorithms such as logistic regression, decision trees, support vector machines (SVM), or neural networks to classify data into two classes.
Sigmoid Function in Binary Classification
In binary classification, one common algorithm used is logistic regression. Logistic regression uses a sigmoid function to map predicted values to probabilities.
Sigmoid Function:
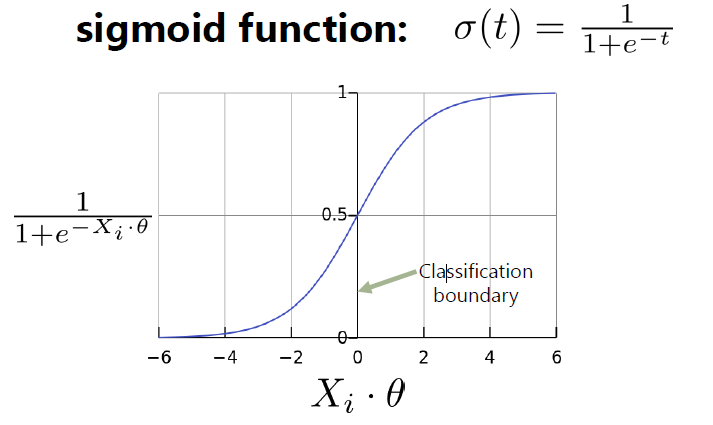
The sigmoid function, also known as the logistic function, is defined as:
$$\sigma(z) = \frac{1}{1 + e^{-z}}$$
where \(z\) is the linear combination of the features and their corresponding weights:
$$z = \beta_0 + \beta_1X_1 + \beta_2X_2 + ... + \beta_nX_n$$
Interpretation:
The sigmoid function outputs a value between 0 and 1, representing the probability of the positive class.
If the output of the sigmoid function is greater than 0.5, we classify the data point as belonging to the positive class.
If the output is less than or equal to 0.5, we classify the data point as belonging to the negative class.
Example:
Let's say we have a binary classification problem where we want to predict whether a student will pass \((1)\) or fail \((0)\) an exam based on the number of hours they studied.
Features: Hours studied \(X\)
Target variable: Pass \((1)\) or Fail \((0)\)
We use logistic regression to model this problem:
$$P(\text{Pass}) = \sigma(\beta_0 + \beta_1X) = \frac{1}{1 + e^{-(\beta_0 + \beta_1X)}}$$
\(P(\text{Pass}): \text{is the probability of passing the exam}\)
\(X : \text{is the number of hours studied}\)
\(\beta_0 \text{ and } \beta_1: \text{are the coefficients of the logistic regression model}\)
For example, if \(\sigma(\beta_0 + \beta_1X) = 0.8\), it means that the probability of passing the exam is \(80%\), and we classify the student as likely to pass.
The sigmoid function allows us to map the output of the logistic regression model to probabilities, making it suitable for binary classification problems.
Multi-class Classification
Multi-class classification is a supervised learning technique used to classify data into more than two distinct categories or classes. The model is trained on a labeled dataset, where each input data point is associated with one of the multiple classes. The goal of multi-class classification is to predict the correct class label for new, unseen data points based on their features.
Equation:
Multi-class classification models use various algorithms, such as softmax regression (multinomial logistic regression), decision trees, support vector machines (SVM), or neural networks, to classify data into multiple classes.
Softmax Function in Multi-class Classification
In multi-class classification, the softmax function is used to convert the raw output of a model into probabilities for each class. It is especially useful when the output can belong to one of several possible classes.
Softmax Function:

The softmax function transforms a vector of arbitrary real-valued scores into probabilities. It achieves this by exponentiating the score of each class and dividing it by the sum of the exponentials of all classes. It is defined as:
$$P(\text{Class } i) = \frac{e^{z_i}}{\sum_{j=1}^{K} e^{z_j}}$$
Where:
\(P(\text{Class } i): \text{is the probability of the input belonging to class ( i )}\)
\(z_i : \text{is the output score (logit) for class ( i )}\)
\( K : \text{is the total number of classes}\)
Interpretation:
The softmax function outputs a probability distribution over the classes.
Each output value represents the probability of the input belonging to the corresponding class.
The output probabilities sum up to 1, making them suitable for classification.
Example:
Let's say we have a multi-class classification problem with three classes: Cat, Dog, and Bird. We have trained a model that outputs the following scores for an input image:
\(z_{\text{Cat}} = 5 \)
\(z_{\text{Dog}} = 3\)
\(z_{\text{Bird}} = 1\)
Using the softmax function, we can calculate the probabilities as follows:
$$P(\text{Cat}) = \frac{e^{5}}{e^{5} + e^{3} + e^{1}} \approx \frac{148.41}{148.41 + 20.09 + 2.72} \approx \frac{148.41}{171.22} \approx 0.866$$
$$P(\text{Dog}) = \frac{e^{3}}{e^{5} + e^{3} + e^{1}} \approx \frac{20.09}{148.41 + 20.09 + 2.72} \approx \frac{20.09}{171.22} \approx 0.117$$
$$P(\text{Bird}) = \frac{e^{1}}{e^{5} + e^{3} + e^{1}} \approx \frac{2.72}{148.41 + 20.09 + 2.72} \approx \frac{2.72}{171.22} \approx 0.016$$
So, the probabilities for the input image belonging to each class are approximately:
\(Cat: 0.866\)
\(Dog: 0.117\)
\(Bird: 0.016\)
The class with the highest probability \((Cat)\) is predicted as the output class. Therefore the input image will be predicted as Cat.
We have now completed the section on supervised learning in this course and anticipate exploring the implementation of these algorithms in the next blog. We encourage you to actively engage with the material by practicing with the provided code snippets. Furthermore, to reinforce your understanding of these concepts, I have prepared a complementary GitHub repository where you can find additional practice questions along with their respective solutions in case you encounter difficulties.
Feel free to explore, contribute, and share the repository with your peers. Your continuous support is greatly appreciated!
Remember to Follow, Like, Share, and Subscribe for future updates. Until next time, happy coding!